Overview
The test case page shows the full story for a single test: current status, why it failed or flaked, how long it ran, how many attempts were made, and the evidence you need to act.
It mirrors Playwright’s layout but adds AI labels, a feedback form, and cleaner attempt-by-attempt views.
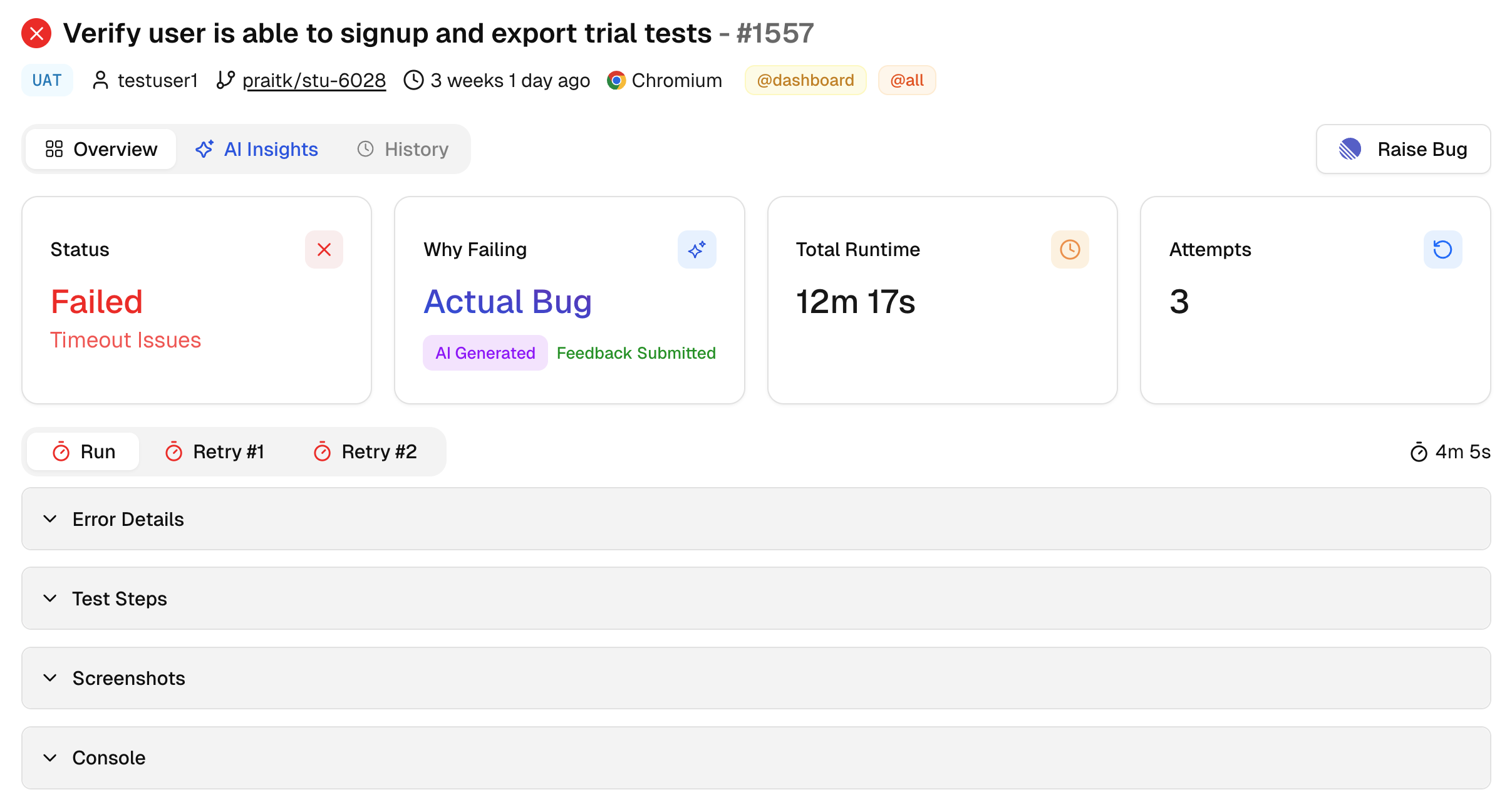
Top metrics
1. Status
Shows the outcome for this test case: Passed, Failed, Skipped, or Flaky. When it is Failed, Flaky, or Skipped, the tile also shows the primary reason, such as Timeout Issues or Element Not Found, so you know the technical cause before reading logs.
2. Why Failing
AI assigns a label like Actual Bug, UI Change, Unstable, or Misc. If the label is off, use Click to modify to open the Test Failure Feedback form, pick the right category, and add context. Your input updates the label for this run and helps future runs classify better.
This form lets you correct the AI label and add context. Choose UI Change, Actual Bug, Unstable, or Miscellaneous, then write a short note if needed.
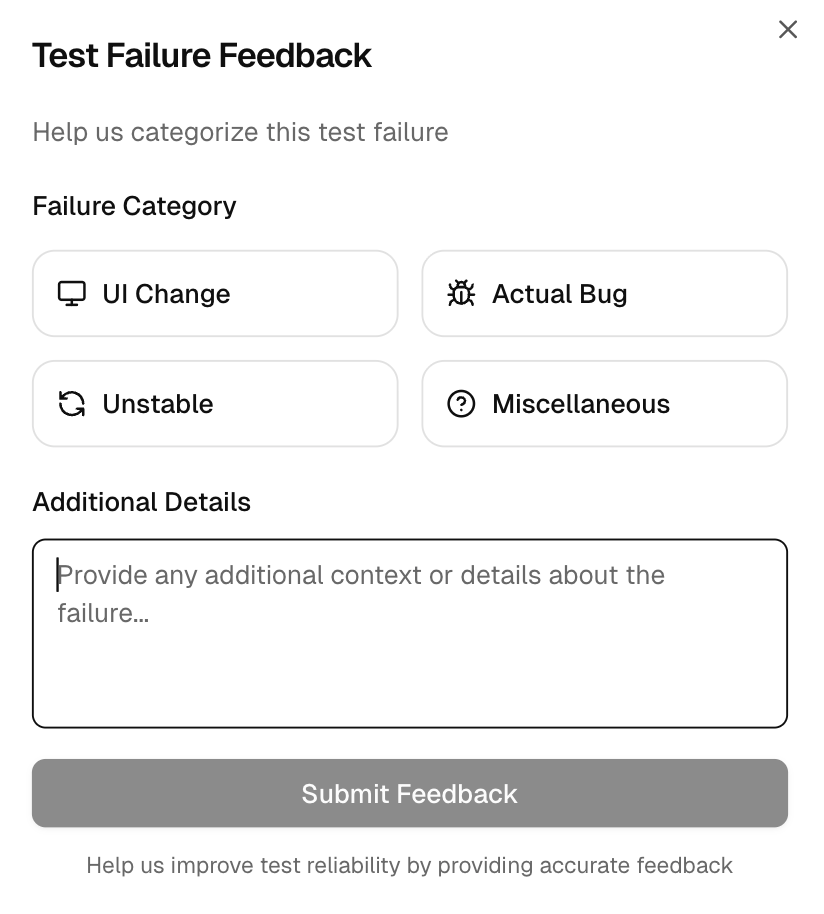
This option is available for failed or flaky tests. Accurate feedback improves future classification and makes the AI Insights page more reliable for your team.
3. Total Runtime
The execution time for this test in the current run. Use it to confirm slowdowns after code or config changes.
4. Attempts
Shows how many times the test ran in this run based on your retry settings. This makes it easy to see if the test stabilized after a retry.
A pass on a later attempt with no code change is a strong Unstable signal. Fix the root cause, but keep the PR moving.
Evidence Panels
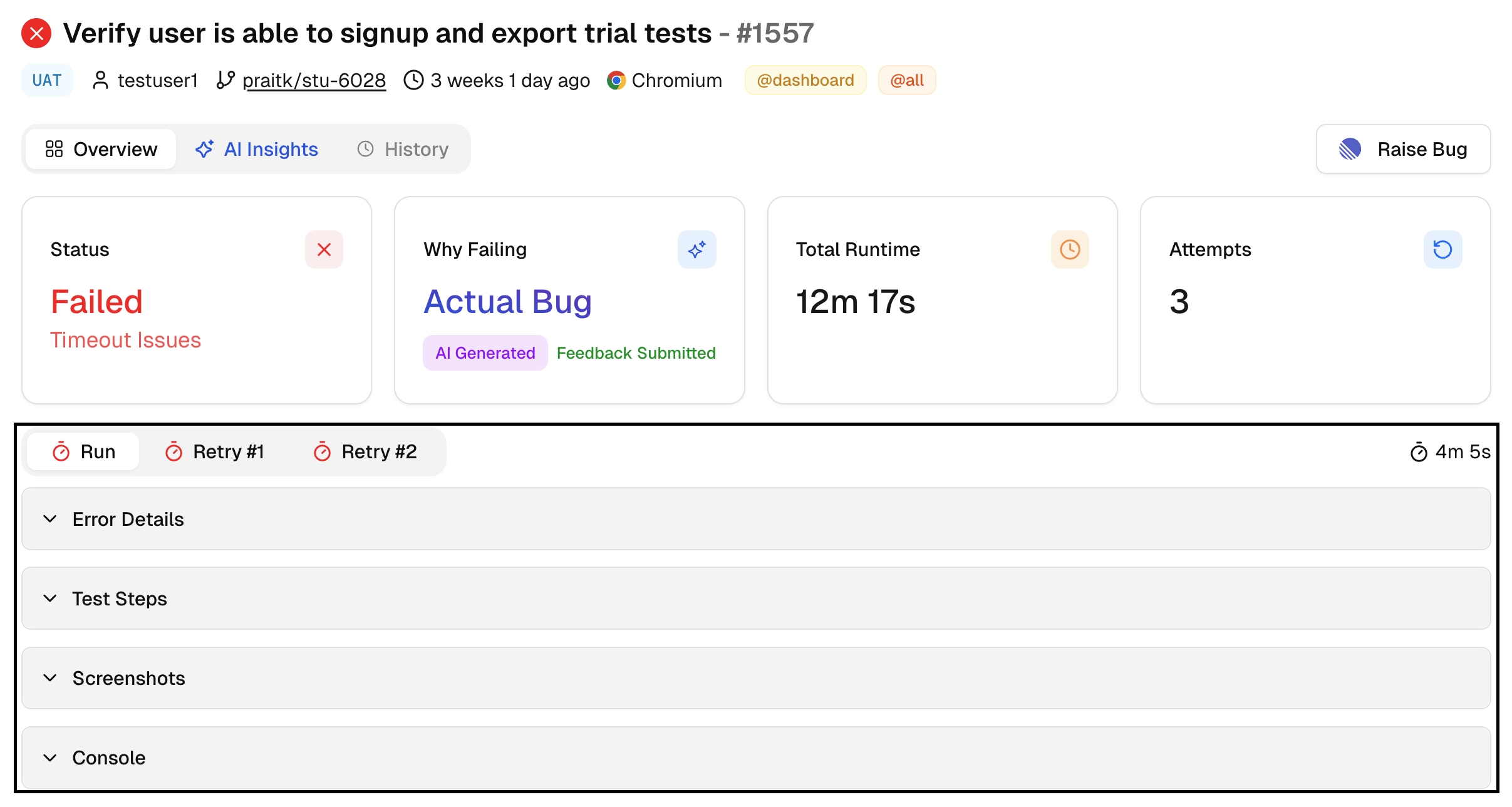
Tabs named Run, Retry 1, Retry 2, switch the view to that specific attempt. Each tab updates the evidence panels below, so you can compare the failing attempt with the passing one and spot what changed.
This is the fastest way to confirm whether a retry only needed more time, a better locator, or a data reset.
-
Error Details: Raw error text with the exact assertion or step that failed. Use it to match the failure to the code path.
-
Screenshots: Captures taken during the test. Helpful for UI state at the point of failure.
-
Console: Browser console output for the attempt. Look here for network or script errors that explain UI symptoms.
AI Insights
AI Insights explains why this test failed or was flaky and what to do next. It is available for failed or flaky tests.
1. Category and Confidence
-
Shows the AI category for the test case, for example Actual Bug, UI Change, Unstable, or Miscellaneous.
-
Displays a confidence score so you know how strongly the model supports the label. If the label looks off, you can correct it on this page and future runs learn from that feedback.
2. AI Recommendations
-
Summarizes the primary evidence from the error messages and logs, then links it to the chosen failure category.
-
Checks recent commits for UI or config changes that might explain the failure, and calls this out if relevant.
-
Points to the most likely cause, for example timing or data issues, so you do not waste time chasing unrelated fixes.
Read AI Insights block first. It tells you whether you are dealing with test noise or a product defect.
3. Recommendations
-
Lists next steps to investigate. These are practical actions tied to the evidence, such as reviewing timing around a step or validating selectors after a change.
-
Designed to be short and ordered, so you can try the highest impact checks first.
4. Historical insight
-
States how the test behaved over the last few runs.
-
If the same failure repeats across runs, AI calls it out as consistent, which often points to timing or setup rather than a one-off defect.
-
If failures started only after a recent change, AI notes the likely start window so you can match it to a commit.
5. Quick Fixes
-
Offers actionable fixes that align with the analysis, for example tightening a selector, adding an explicit wait, or adjusting a timeout.
-
Provides the exact places to change in your test code. Treat these as starting points. Validate locally or in a throwaway branch before merging.
AI Insights is guidance, not a replacement for review. Use it to cut triage time, then verify the fix in your repo and CI.