What you’ll learn
- How to upload Playwright results from Azure DevOps pipelines to TestDino
- How to configure sharded test runs with merged reporting
- How to set up the TESTDINO_TOKEN as a secret pipeline variable
Prerequisites
Before setting up, ensure you have:- A TestDino account with a project created
- A TestDino API key (Generate API Keys)
- An Azure DevOps project with pipelines enabled
- A Playwright test project (or clone the TestDino Example Repository to get started)
- Playwright configured with JSON and HTML reporters in
playwright.config.js:
playwright.config.js
Set Up Your API Key
Store your TestDino API key as a secret pipeline variable so it is available to your pipeline without exposing it in logs or config files.- Open your Azure DevOps pipeline
- Click Edit on the pipeline
- Click Variables
- Click New variable
- Set the name to
TESTDINO_TOKEN - Paste your TestDino API key as the value
- Check Keep this value secret
- Save the pipeline
Basic Pipeline Config
For a simple setup without sharding, add the upload step after your Playwright tests.azure-pipelines.yml — Basic pipeline
azure-pipelines.yml — Basic pipeline
azure-pipelines.yml
Upload Options
Sharded Test Runs
For larger test suites, Azure DevOps matrix strategy splits tests across multiple jobs. Each shard produces a blob report that gets merged before uploading to TestDino.How it works
- Azure DevOps runs Playwright across 4 shards using a matrix strategy
- Each shard publishes its blob report as a pipeline artifact
- A separate
MergeAndUploadstage downloads all blob reports, merges them into a singlereport.json, and uploads to TestDino - The merge stage runs even if some shards fail (
condition: always())
Full sharded config
azure-pipelines.yml — Sharded pipeline
azure-pipelines.yml — Sharded pipeline
azure-pipelines.yml
Info
The
MergeAndUpload stage uses dependsOn: Test with condition: always() so it runs even when some shards fail. The upload step also checks if the merged report exists before attempting the upload, avoiding unnecessary errors.Key details in the sharded config
Pipeline execution
After the pipeline runs, Azure DevOps shows all shard jobs and the merge stage in the pipeline view.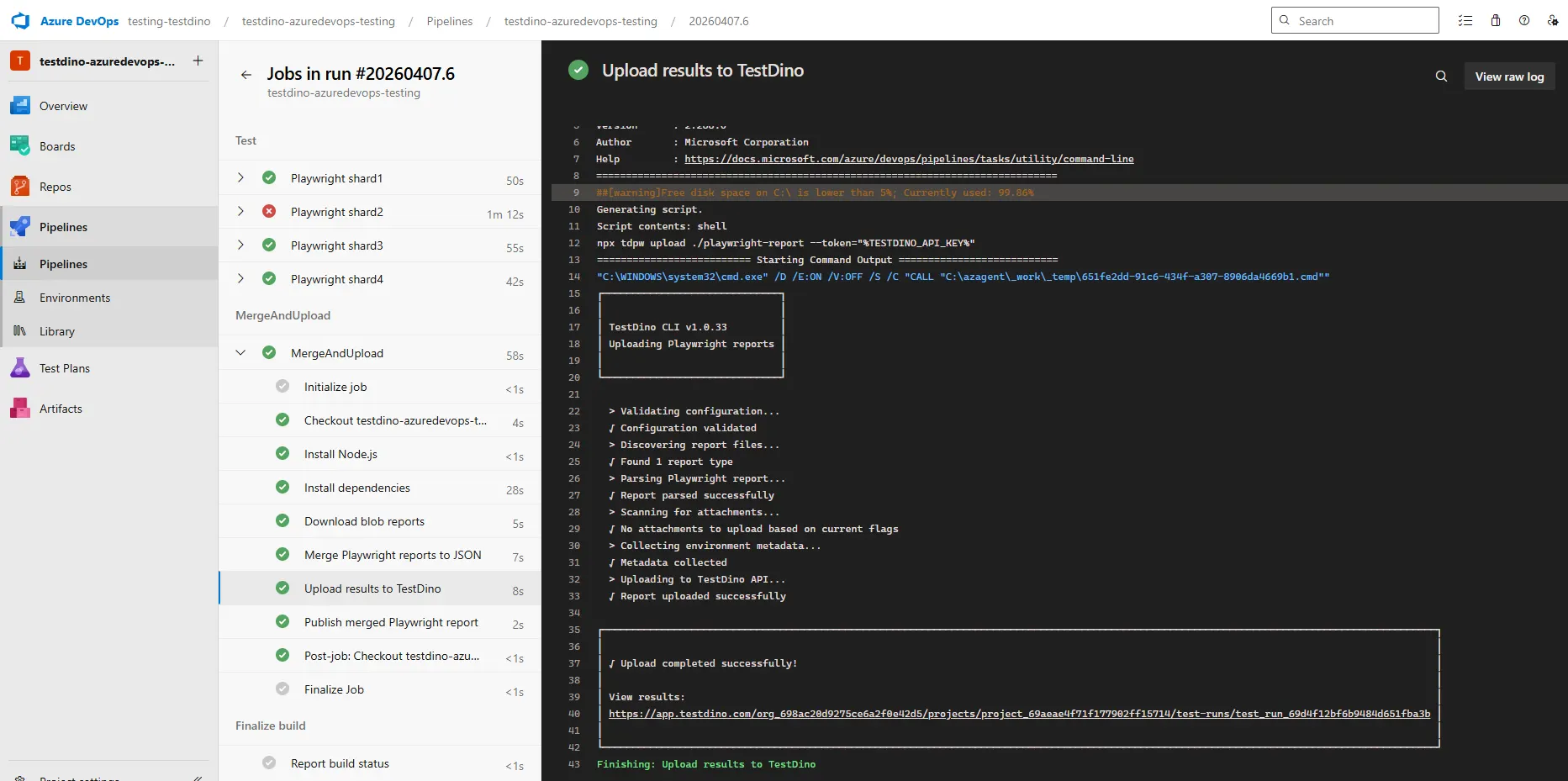
Results in TestDino
Once uploaded, the test run appears in your TestDino dashboard with full failure details, flaky detection, and trend data.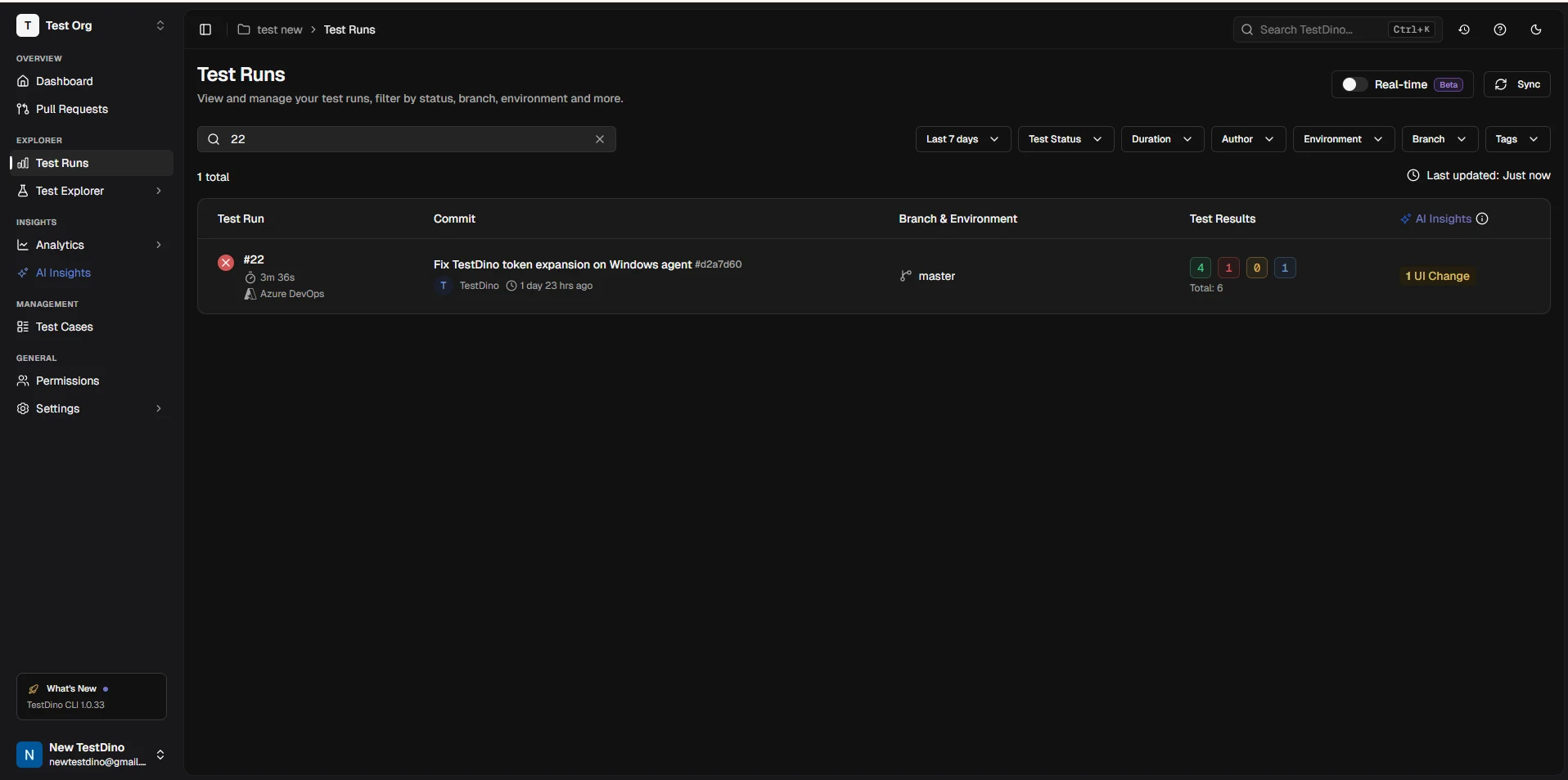
Rerun Failed Tests
Cache test metadata to enable selective reruns:Troubleshooting
Upload step skipped after test failure
Upload step skipped after test failure
- Add
condition: always()to the upload step so it runs regardless of test exit code - For sharded runs, ensure the
MergeAndUploadstage hascondition: always()anddependsOn: Test
No report found at ./playwright-report
No report found at ./playwright-report
- Verify your
playwright.config.tsoutputs toplaywright-report/(default location) - For sharded runs, ensure all shards publish
blob-reportas a pipeline artifact and the merge step writes toplaywright-report/
TESTDINO_TOKEN not available in script
TESTDINO_TOKEN not available in script
- Secret variables in Azure DevOps are not automatically available as environment variables. You must map them explicitly using the
envblock in the script step - Verify the variable name matches exactly:
TESTDINO_TOKEN: $(TESTDINO_TOKEN)
Blob reports not found during merge
Blob reports not found during merge
- Ensure each shard uses
PublishPipelineArtifactwithcondition: always()to publish even on failure - The
DownloadPipelineArtifactstep uses patternblob-report-*/*. Verify artifact names match this pattern. - Check that
blob-reportdirectory exists after running Playwright (configurereporter: [['blob']]inplaywright.config.ts)
Next Steps
CI Optimization
Reduce CI time with smart reruns
Branch Mapping
Map branches to environments for organized test runs
Integrations
Connect Slack, Jira, Linear, Asana, and more
Azure DevOps Extension
View test runs inside Azure DevOps