Setup
Test Audit runs through the TestDino MCP Server. Once MCP is configured, every audit is a single prompt to your AI agent.1
Set up the TestDino MCP server
Follow MCP Overview to install the server, generate a PAT, and configure your client.
Skip this step if MCP is already working in your client.
2
Open your repo and run the audit prompt
Open the Playwright repo in your IDE so the agent can read your test files. Then send one of these prompts:
Critical and High issues are always reported, even outside the chosen scope.
3
View the audit in TestDino
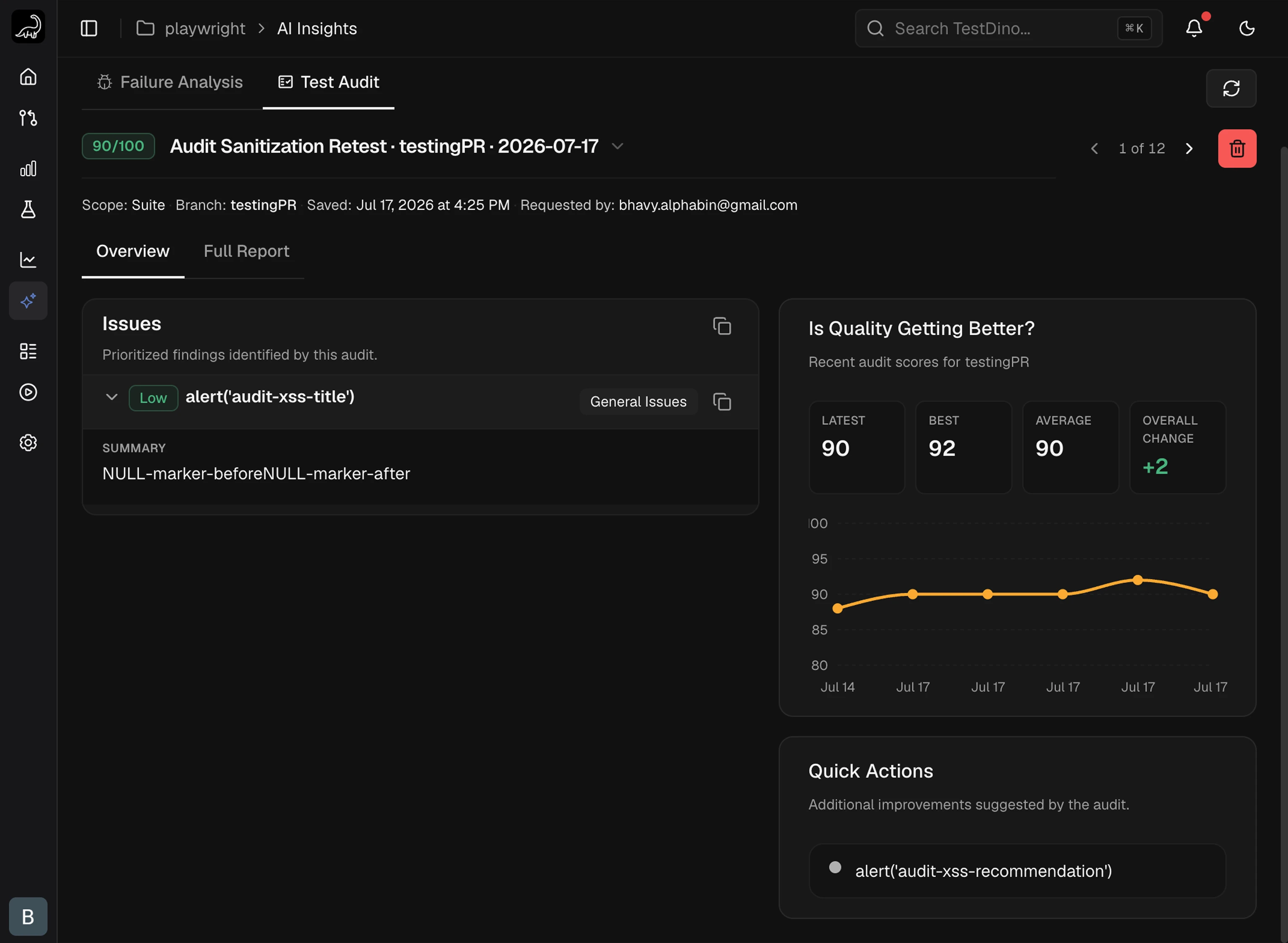
Open AI Insights → Test Audit in TestDino ↗. The new audit appears at the top of the history with the score, issues, and full report.
Reading the Report
Audit Score
Every audit returns a single 0–100 score.
A suite with multiple Critical issues cannot reach the Excellent band even if other dimensions look healthy.
Overview Tab
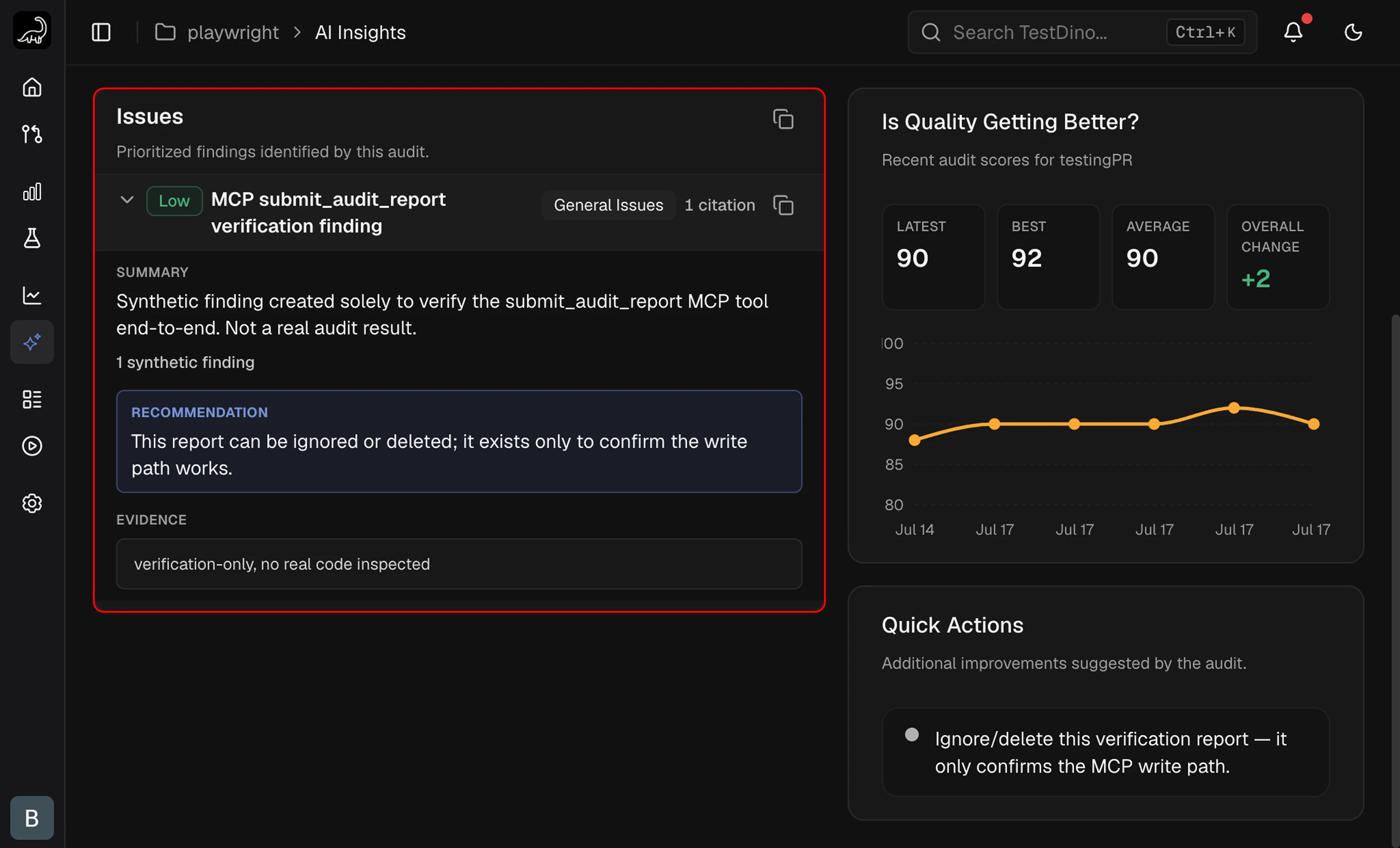
The Overview tab splits the audit into two panels side by side: a prioritized Issues list on the left and a Quick Actions sidebar on the right.Issues
Each Issue card collapses to a single row with the severity badge, title, category badge, and citation count. Expanding the card reveals three blocks:- Summary: what the issue is and why it matters.
- Recommendation: a concrete fix, often a one-line change at a
file:linereference. - Evidence: one or more
file:linereferences, each with a short observation.
Quick Actions
A sidebar listing up to four lightweight improvements that fall outside the main Issues. Suggestions are free-text and do not carry severity, category, or evidence metadata.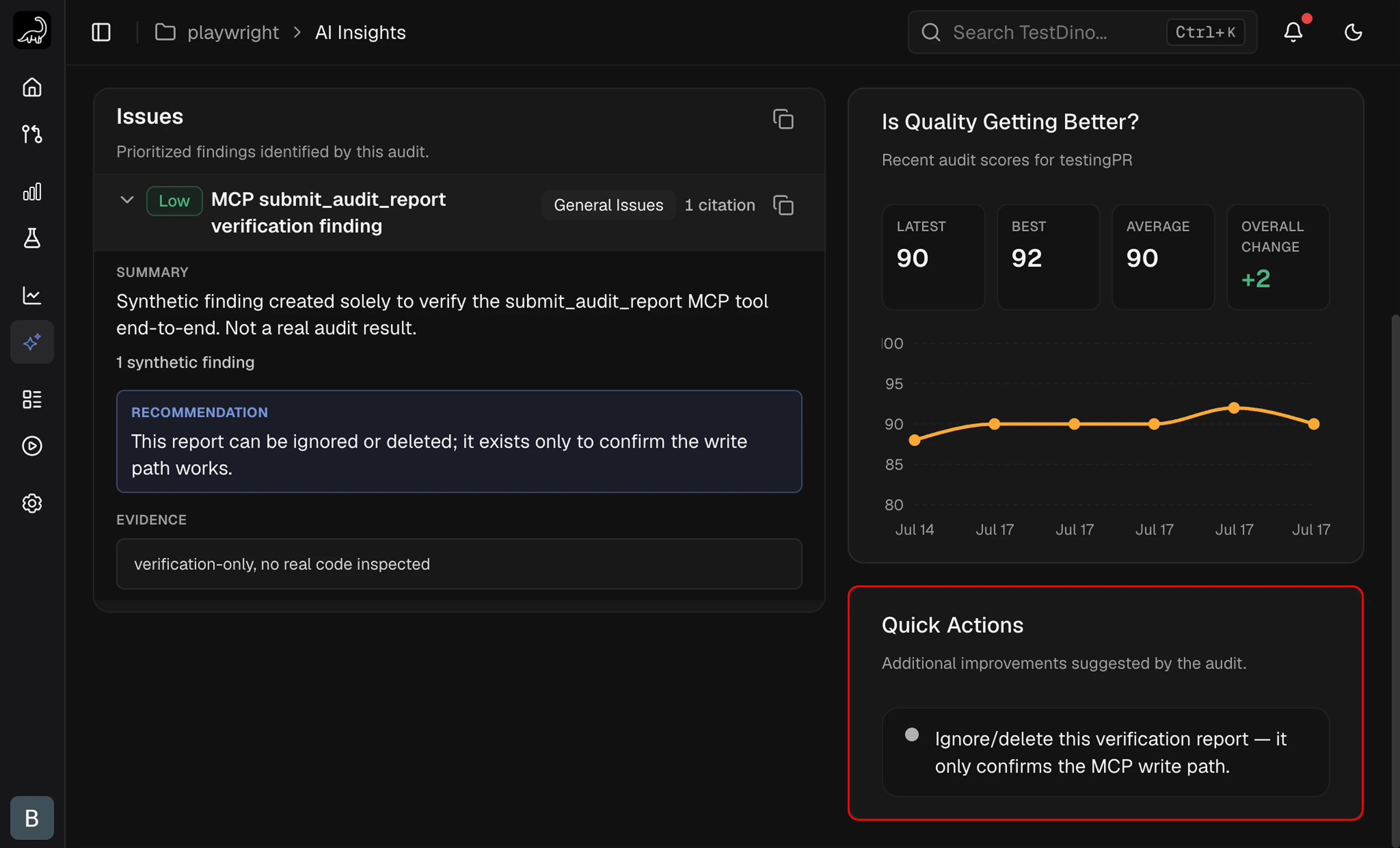
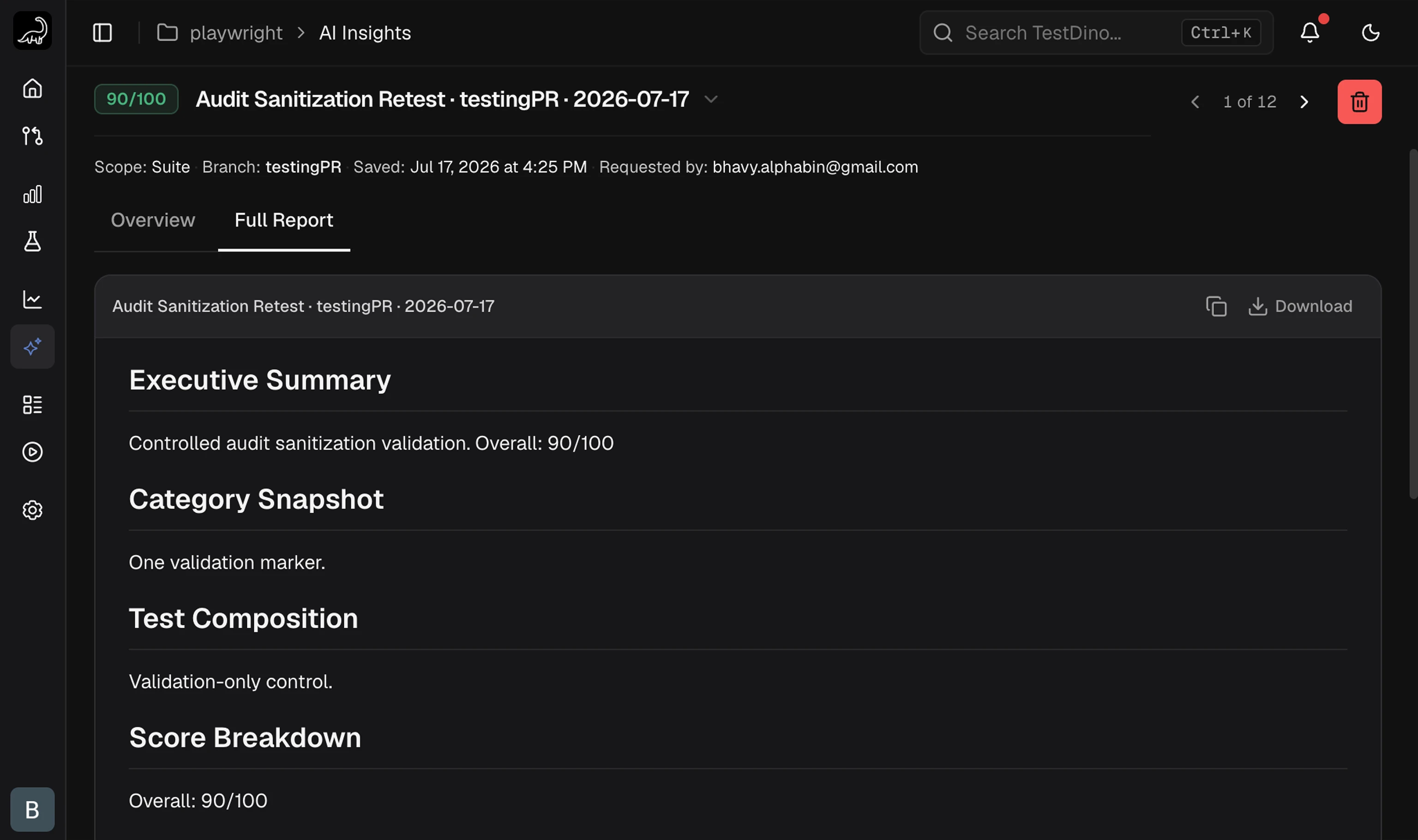
Full Report Tab
The Full Report tab renders the complete markdown audit document. Use the Download button to save it as a.md file for pull-request reviews or wikis.
Categories and Severity
Issue Categories
Each finding is tagged with one of nine categories.Severity Levels
A scope with more than 50% surface-level tests is automatically reported as Critical.
Audit History
Past audits are stored per project and shown in the picker at the top of the Test Audit tab.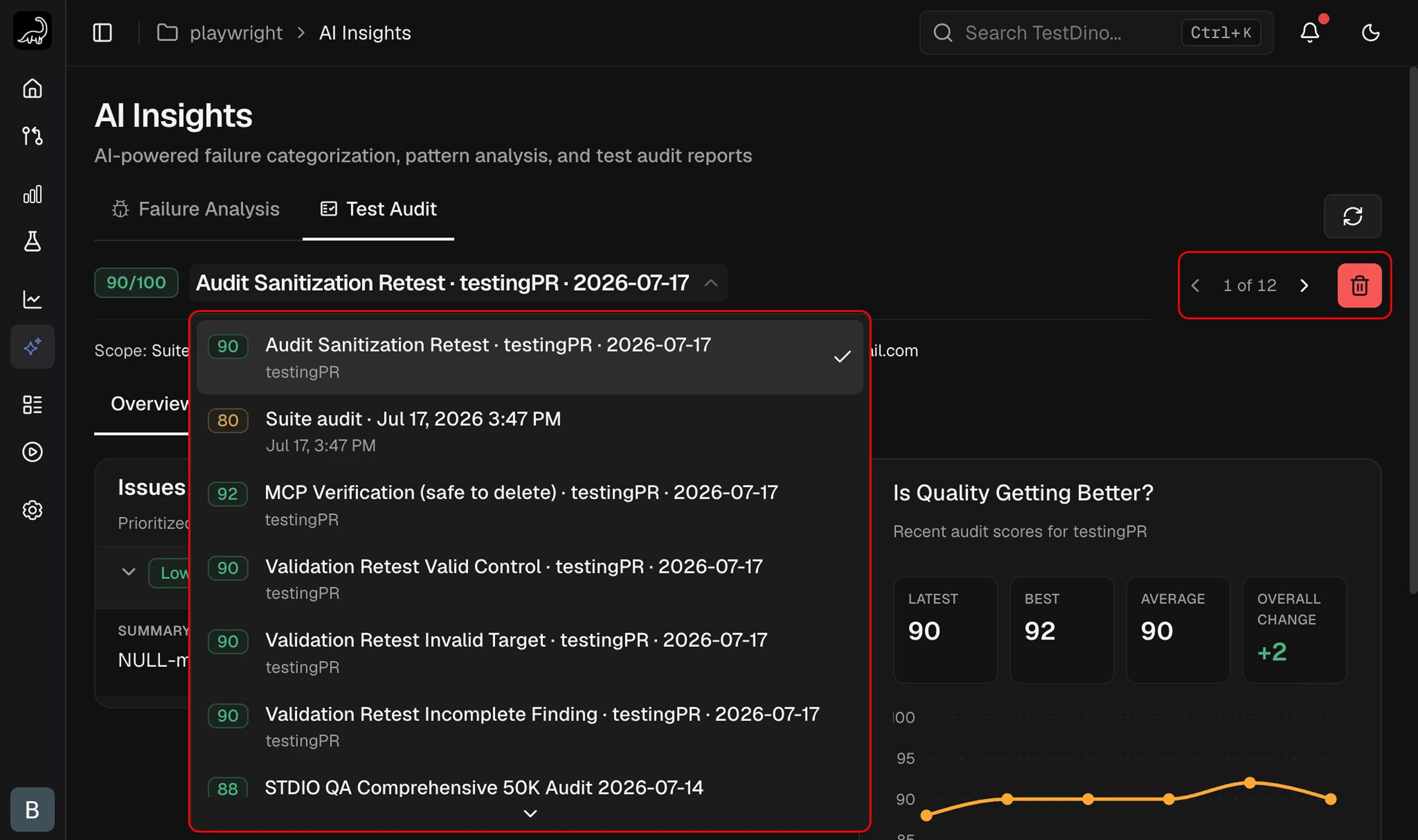
- Navigate: use the
<and>arrows, or open the dropdown to jump to any audit. - Pagination: 10 audits per page.
- Select: click any past audit to load its Overview and Full Report.
- Delete: the trash icon removes the selected audit. This cannot be undone.
- Re-run: ask your AI agent for a new audit at any time. New reports are added to history without overwriting previous ones.
Related
Failure Analysis
Cross-run failure categorization and patterns
MCP Overview
Connect AI agents to TestDino
MCP Tools Reference
All MCP tool specifications
Test Run AI Insights
Per-run failure categorization
Test Case AI Insights
Per-case AI diagnosis
Project Settings
AI controls and access tokens